0. TL;DR
문제
- 리포트 페이지에서 최대 10초 가량의 인터렉션 블로킹 문제 발생
- 원인: Carpet 그래프에서 400만개 가량의 히트맵 데이터 변환
해결
- 우선 히트맵 데이터 변환 로직 처리를 서버 사이드로 전환하여 블로킹 문제 해결
- 이후 추가 개선을 위해 함수 호출 오버헤드 제거
느낀 점
- 우선순위를 고려해서 단계적으로 최적화하기
- 데이터 기반 측정의 중요성
- 시간 복잡도를 고려해서 코드를 작성할 것
1. 문제
지난 10월 압연 공정 모니터링을 개발하던 도중, 시스템 리포트 페이지에 진입할 때 최대 10초 이상 브라우저가 블로킹되는 심각한 성능 문제를 발견했습니다. 이 글에서는 해당 문제를 어떻게 해결했는지, 그리고 단계적 최적화를 통해 어떤 성과를 얻었는지 공유하고자 합니다.

Carpet 그래프의 1줄을 그리기 위해 API에서 받아오는 데이터는 각 센서별로 다음과 같은 구조였습니다.
const initialData = [
[
[1, 2, 3, ...], // 시간
["A", "B", "C", ...], // 라벨
[25.5, 26.1, 25.8, ...] // 측정값(예시)
],
[
[1, 2, 3, ...],
["A", "B", "C", ...],
[30.2, 29.8, 30.5, ...]
],
//...
];
하지만 uPlot 라이브러리에서 히트맵을 그리기 위해서는 다음과 같은 2차원 매트릭스 형태가 필요했습니다.
const uPlotData = [
[1, 2, 3, 4, 5, ...], // X축 (시간)
[25.5, 26.1, 25.8, ...], // Label의 값
[30.2, 29.8, 30.5, ...],
//...
];이를 위해서 useEffect를 사용해서 uPlot의 형식으로 변경해주도록 했습니다.
useEffect(() => {
if (isDataReady && dataSource?.length > 0) {
// 1단계: 빈 매트릭스 생성
const vMatrix: number[][] = yVals.map(() => xVals.map(() => 0));
// 2단계: 실제 데이터로 값 대입
initialData.forEach((dataRow, rowIndex) => {
dataRow[0].forEach((time, colIndex) => {
const value = dataRow[2][colIndex];
vMatrix[rowIndex][colIndex] = value;
});
});
// 3단계: uPlot 형식으로 변환
const uPlotAlignedData = [xVals, ...vMatrix];
setUplotData(uPlotAlignedData);
}
}, [isDataReady, dataSource]);문제는 1개의 Carpet 그래프 별로 44개의 api를 호출했으며, 각 api마다 1만개가 넘는 데이터를 호출하고 있었다는 것입니다. 1개의 Carpet 그래프만을 테스트했을때는 크게 체감을 하지 못했습니다. 하지만 시스템 리포트 페이지에서는 최대 8개의 Carpet 그래프를 한번에 출력하면서 400만개 가량의 데이터를 변환시켜야 했고, 그 결과 최대 10초 이상 브라우저가 블로킹되는 현상이 발생했습니다.
2. 해결 과정
1. 성능 프로파일링
우선 해당 상황에서 Chrome DevTools의 Performance monitor를 확인하자 블로킹이 일어나는 동안 CPU usage가 99.9%로 유지되는 것을 확인할 수 있었습니다. 이를 보고 클라이언트에서 데이터 처리 로직으로 인해 인터렉션 블로킹이 일어나는 것을 확신할 수 있었습니다.
2. 서버 사이드로 데이터 처리 로직 이전
납품 직전에 투입된 상황이였기에, 최대한 빠르게 사용자가 불편함을 느낄 수 없도록 하는게 최우선이라고 생각했습니다. 이에 next.js의 route handler를 사용해서 데이터 처리 로직을 서버 사이드로 넘기는 방식으로 코드를 수정했고, 클라이언트에서는 가공이 완료된 데이터를 받아서 상태를 설정만 해주도록 수정했습니다.
useEffect(() => {
// 서버에서 이미 가공 완료된 데이터를 단순히 설정만
const { uPlotAlignedData, vMatrix, xVals, yVals } = processedData;
setPlotData(uPlotAlignedData); // 즉시 설정 가능
setValueMatrix(vMatrix);
// ... 기타 상태 설정
}, [processedData]);3. 함수 호출 오버헤드 제거
하지만 서버에서 여전히 비효율적인 코드를 사용하고 있다는 문제점이 남아 있었습니다. 납품이 완료된 후, QA 기간에 해당 문제를 추가적으로 개선할 수 있었습니다.
// 매트릭스 초기화: map 체이닝 → Array.from + fill (440,044번 → 44번)
const vMatrix: number[][] = Array.from({ length: yVals.length }, () =>
new Array(xVals.length).fill(0)
);
initialData.forEach((dataRow, rowIndex) => {
const timeArray = dataRow[0];
const valueArray = dataRow[2];
const targetRow = vMatrix[rowIndex];
// 데이터 할당: 내부 forEach → for 루프 (440,000번 콜백 → 0번)
for (let index = 0; index < timeArray.length; index++) {
targetRow[index] = valueArray[index];
}
});위와 같이 수정한 이유는 "함수 호출 오버헤드"를 제거하기 위해서였습니다. 기존 코드에서는 map을 사용해서 빈 매트릭스를 생성하고, forEach를 사용해서 매번 콜백 호출이 이뤄져 함수 호출 오버헤드가 발생했습니다.
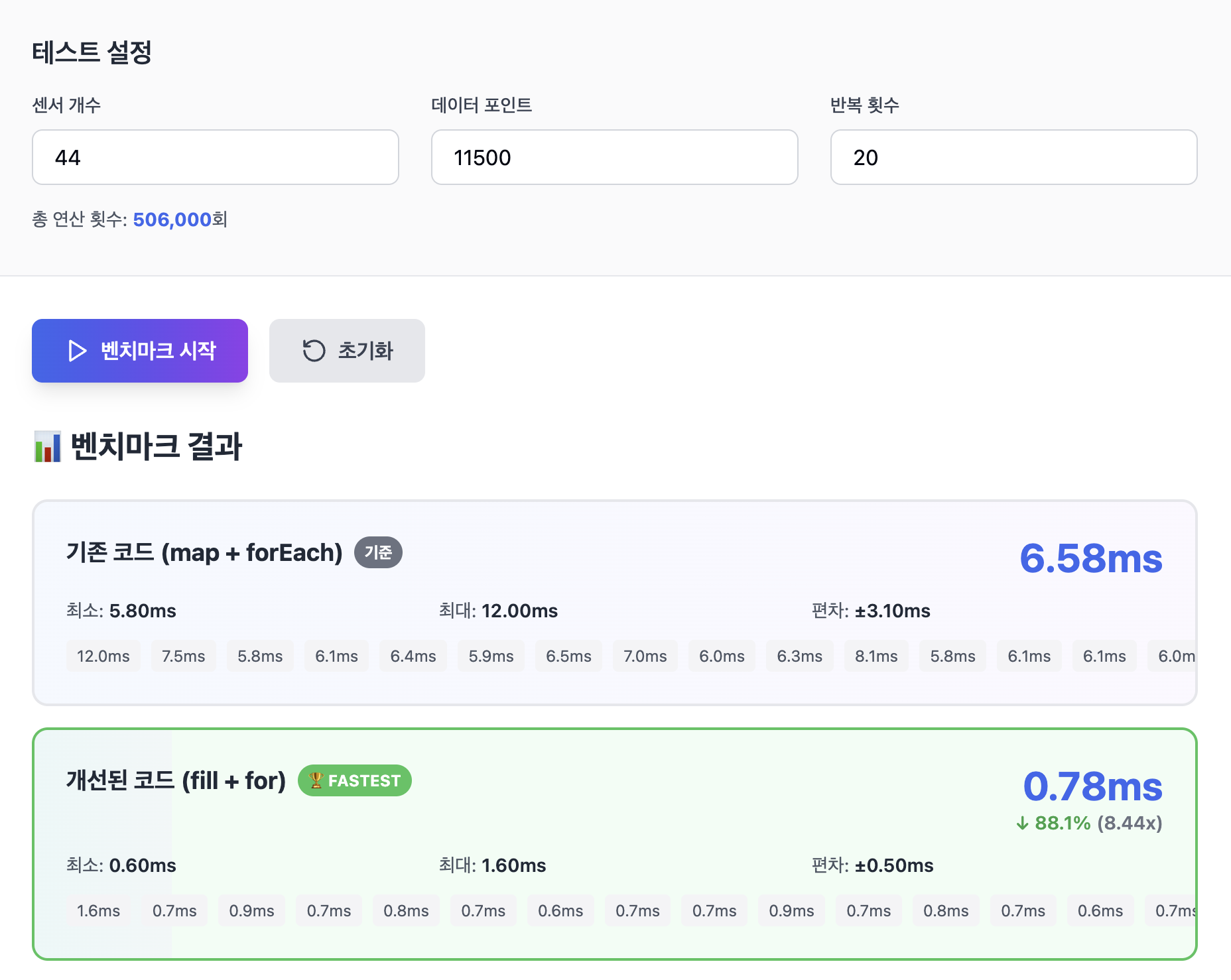
claude로 테스트해본 결과 50만번의 연산 기준으로 10배 가까운 차이가 발생하고 있었습니다. 왜 이런 차이가 발생하게 될까요? Js에서는 하나의 함수가 호출될 때 마다 다음의 과정이 이뤄집니다.
- 실행 컨텍스트 생성
- 스코프 체인 생성
- this 바인딩
- arguments 객체 생성
- 매개변수 할당
- 실행
- 실행 컨텍스트 제거
적은 횟수만 처리된다면 별 문제가 아니지만, 현재처럼 수십만~수백만번 반복해서 호출하는 경우 큰 차이로 이어지게 되는 것입니다.
3. 느낀 점들
1. 우선순위를 고려한 개발
납품 직전이라는 긴급 상황에서 가장 중요한 것은 빠르게 사용자 경험을 개선하는 것이었습니다. 처음부터 완벽한 최적화보다는 우선 클라이언트 블로킹을 제거하는 데 집중했고, 이후 여유가 생겼을 때 서버 성능까지 개선할 수 있었습니다. 모든 문제를 한 번에 해결하려 하기보다는 단계적으로 접근하는 것이 효과적이었던 것 같습니다.
2. 측정의 중요성
사실 저는 Chrome DevTools에서 Performance monitor의 존재조차 제대로 모르고 있다가 이번에 시니어 개발자님이 알려주셔서 처음 사용해보게 되었습니다. 이를 통해서 CPU 사용률 99.9%를 눈으로 본 이후에 문제를 명확하게 인식할 수 있었습니다. 또한, 성능을 최적화하는 것에서도 데이터를 기반으로 측정해가며 최적화 여부를 확인했기에 개선 효과 검증이 가능했습니다. 이후에도 추측 대신 측정을 해가면서 개발해보려고 합니다.
3. 시간 복잡도를 고려하여 개발하기
지금까지는 Js를 사용하면 함수형 프로그래밍의 철학에 따라 map, forEach 같은 함수형 메서드로 개발하는 것이 더 낫다고 생각했습니다. 사실 지금도 대부분의 경우에는 맞는 말이라고 생각합니다. 하지만 수십만 건 이상의 데이터를 처리하는 이번 경우에는 함수형 메서드 대신, for 루프를 직접 사용하는 경우가 더 적합했습니다. 상황에 따라서 시간 복잡도를 고려하며 개발하는 것의 중요성을 깨달을 수 있었습니다.
'개발 > Frontend' 카테고리의 다른 글
| 우리는 어째서 Virtual DOM을 사용하는가? (1) | 2025.08.05 |
|---|---|
| 액션, 계산 분리해보기(함수형 프로그래밍) (0) | 2024.01.08 |
| Vite를 사용하면서 svg 컴포넌트로 만들기 (0) | 2024.01.01 |
| Eslint와 Prettier 설정하기(React + Ts 사용) (0) | 2023.12.31 |
| Interface VS Type / TypeScript (1) | 2023.12.18 |


